First of all, thanks for all the effort to research and model this!
A friend of mine did some modeling as well, and came to the conclusion that there should be a treble increase, rather than the perceived decrease:
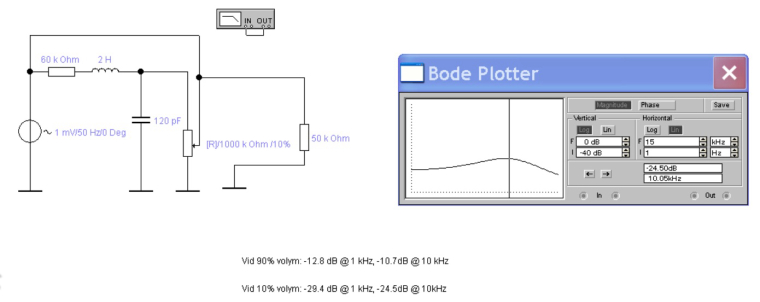
Even though the exact values differ from your (probably more correct) model, the effect is clear.
So, what could we really conclude from all this? That our models are too simplistic? It seems like they contradict your empirical tests? One indication of the complexity is the fact that in your real recording example, the 12th and 13th component is really louder in the rolled-off case, right?
Thanks